Reduce query round trips with improved one-to-many relations
Addressing the N+1 problem and navigating one-to-many relationships with Xata's new approach.
Written by
Alejandro Martínez Vieites
Published on
September 1, 2023
As our launch week comes to a close, we're looking at APIs and their intricate relationships. Today, we're introducing a new syntax that simplifies navigating these relationships. While Xata already provides a great way to retrieve related data using link columns for the many-to-one relationship, we're addressing the challenge of navigating the reverse relationship (one-to-many). This new approach improves efficiency and helps avoid the N + 1 problem.
Let's consider a basic schema. Within the schema, there's a Posts table containing certain information and establishing a connection to the corresponding author. This author-related data belongs in the Users table.
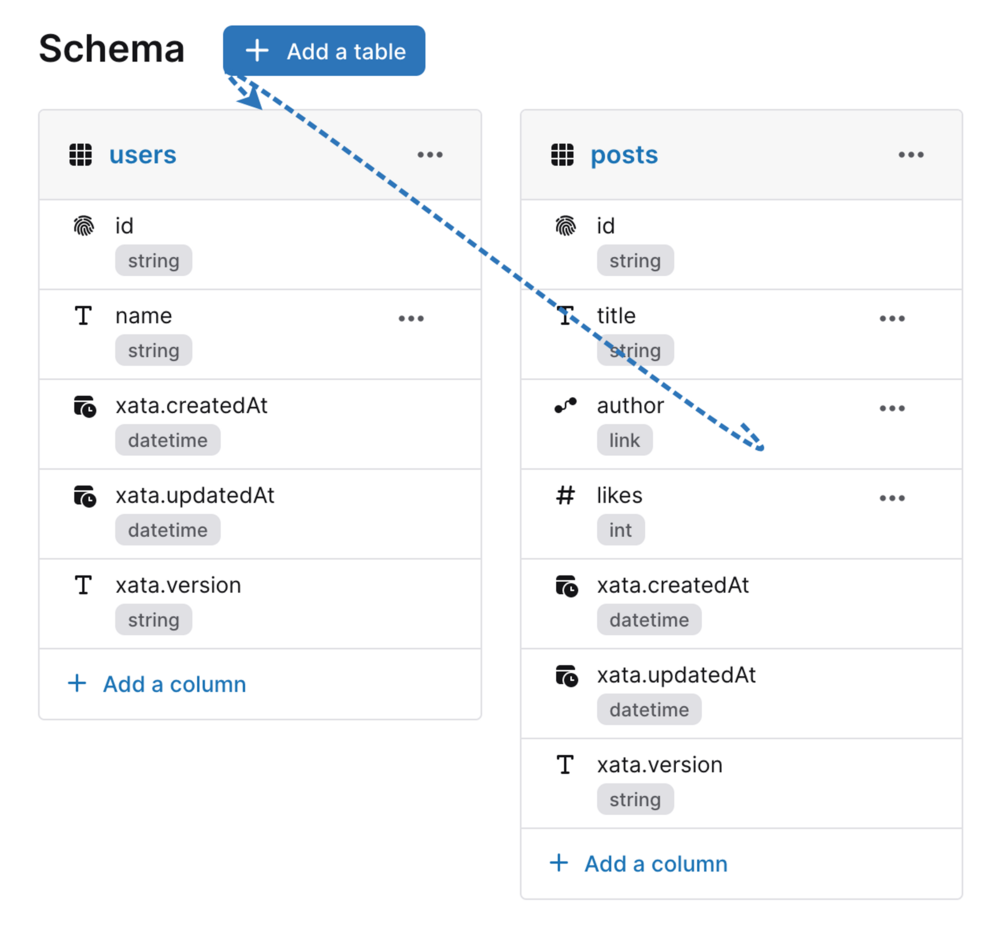
When querying the Posts table we are able to retrieve the title, likes, and the author's name (and any other fields present in the Users table):
const records = await xata.db.posts
.select(["*", "author.*"])
.getAll();records = xata.data().query("posts", {
"columns": ["*","author.*"]
})// POST /db/blogs:main/tables/posts/query
{
"columns": ["*", "author.*"]
}// Response (xata fields have been omitted for clarity)
{
"records": [
{
"author": {
"id": "rec_cie05krjtojbm41fv2q0",
"name": "Tudor Golubenco"
},
"id": "rec_cie05srjtojbm41fv2t0",
"likes": 13,
"title": "Postgres schema changes are still a PITA"
},
{
"author": {
"id": "rec_cie05krjtojbm41fv2q0",
"name": "Tudor Golubenco"
},
"id": "rec_cie05v3jtojbm41fv2tg",
"likes": 15,
"title": "On the performance impact of REPLICA IDENTITY FULL in Postgres"
},
{
"author": {
"id": "rec_cie05ljjtojbm41fv2qg",
"name": "Joan Edwards"
},
"id": "rec_cie060jjtojbm41fv2u0",
"likes": 5,
"title": "Introducing the new Xata regions: Sydney & Frankfurt"
},
{
"author": {
"id": "rec_cie05krjtojbm41fv2q0",
"name": "Tudor Golubenco"
},
"id": "rec_cii1kajjtoj0t82ae3ag",
"likes": 6,
"title": "Semantic or keyword search for finding ChatGPT context. Who searched it better?"
},
{
"author": {
"id": "rec_cii1ki3jtoj0t82ae3b0",
"name": "Alex Francoeur"
},
"id": "rec_cii1kjjjtoj0t82ae3bg",
"likes": 9,
"title": "The next era of databases are serverless, adaptive, and collaborative"
},
{
"author": {
"id": "rec_cii1ki3jtoj0t82ae3b0",
"name": "Alex Francoeur"
},
"id": "rec_cii1kpbjtoj0t82ae3c0",
"likes": 8,
"title": "End-to-end preview deployment workflows with Xata and Vercel"
},
{
"author": {
"id": "rec_cii1ki3jtoj0t82ae3b0",
"name": "Alex Francoeur"
},
"id": "rec_cii1l1rjtoj0t82ae3cg",
"likes": 20,
"title": "Modern database workflows with GitHub, Vercel, Netlify, and Xata"
}
]
}What if we wanted to list the authors and their posts? You would need to query the Users table in order to retrieve all authors:
const records = await xata.db.users
.select(["*"])
.getAll();records = xata.data().query("posts", {
"columns": ["*"]
})// POST /db/blogs:main/tables/users/query
{
"columns": ["*"]
}// Response (Xata fields have been omitted for clarity)
{
"records": [
{
"id": "rec_cie05krjtojbm41fv2q0",
"name": "Tudor Golubenco"
},
{
"id": "rec_cie05ljjtojbm41fv2qg",
"name": "Joan Edwards"
},
{
"id": "rec_cii1ki3jtoj0t82ae3b0",
"name": "Alex Francoeur"
}
]
}And then, for each user that has been returned, make a separate request in the Posts table to retrieve the posts from each author, similar to:
const records = await xata.db.posts
.select(["*"])
.filter({ author: "rec_cie05krjtojbm41fv2q0"})
.getAll();records = xata.data().query("posts", {
"columns": ["*"],
"filter": {
"author": "rec_cie05krjtojbm41fv2q0"
}
})// POST /db/blogs:main/tables/posts/query
{
"columns": ["*"],
"filter": {
"author": "rec_cie05krjtojbm41fv2q0"
}
}// Response (Xata fields have been omitted for clarity)
{
"records": [
{
"author": {
"id": "rec_cie05krjtojbm41fv2q0"
},
"id": "rec_cie05srjtojbm41fv2t0",
"likes": 13,
"title": "Postgres schema changes are still a PITA"
},
{
"author": {
"id": "rec_cie05krjtojbm41fv2q0"
},
"id": "rec_cie05v3jtojbm41fv2tg",
"likes": 15,
"title": "On the performance impact of REPLICA IDENTITY FULL in Postgres"
},
{
"author": {
"id": "rec_cie05krjtojbm41fv2q0"
},
"id": "rec_cii1kajjtoj0t82ae3ag",
"likes": 6,
"title": "Semantic or keyword search for finding ChatGPT context. Who searched it better?"
}
]
}We are performing "1" (get the authors) + "N" (get the authors's posts) requests. This is inconvenient and also quite inefficient, since the number of requests depends on the number of user records.
There are workarounds depending on the data set and the amount of code we are willing to write, like getting all the authors and all the posts, or using the IN operator and then processing the response in the app. But it would be better if our API helped us get exactly what we want.
Since the relationship is already defined by the link column, it’s a matter of providing a good API experience to get this data more easily. We have introduced column expressions in the query endpoint so the columns field is no longer restricted to a list of column names. Now we are able to provide a JSON object to better define the projection we want.
To better understand this concept, let's improve on the previous example to showcase the benefits of navigating relationships in reverse using column expressions:
const records = await xata.db.users
.select(["*", {
"name": "<-posts.author",
"columns": ["title"]
}])
.getAll();records = xata.data().query("posts", {
"columns": [
"*",
{
"name": "<-posts.author",
"columns": ["title"]
}
]
})// POST /db/blogs:main/tables/users/query
{
"columns": [
"*",
{
"name": "<-posts.author",
"columns": ["title"]
}
]
}In this request we are asking for all the fields in the Users table (*) plus a column expression. The expression consists of a structure with two fields:
-
name: When using the<-prefix, it signifies that we are navigating in reverse along the link defined by theauthorcolumn in the Posts table. This reverse navigation establishes a one-to-many relationship between the linked records. -
columns: Thecolumnsfield defines the projection to be applied to the table on the opposite side of this relationship. It specifies which fields from the related table should be included in the query result.
What we get back is a list of post data nested in every author record. The default name for the nested list is postsauthor (i.e. table name + link name):
// Response (xata fields have been omitted for clarity)
{
"records": [
{
"id": "rec_cie05krjtojbm41fv2q0",
"name": "Tudor Golubenco",
"postsauthor": {
"records": [
{
"id": "rec_cie05srjtojbm41fv2t0",
"title": "Postgres schema changes are still a PITA"
},
{
"id": "rec_cie05v3jtojbm41fv2tg",
"title": "On the performance impact of REPLICA IDENTITY FULL in Postgres"
},
{
"id": "rec_cii1kajjtoj0t82ae3ag",
"title": "Semantic or keyword search for finding ChatGPT context. Who searched it better?"
}
]
}
},
{
"id": "rec_cie05ljjtojbm41fv2qg",
"name": "Joan Edwards",
"postsauthor": {
"records": [
{
"id": "rec_cie060jjtojbm41fv2u0",
"title": "Introducing the new Xata regions: Sydney & Frankfurt"
}
]
}
},
{
"id": "rec_cii1ki3jtoj0t82ae3b0",
"name": "Alex Francoeur",
"postsauthor": {
"records": [
{
"id": "rec_cii1kpbjtoj0t82ae3c0",
"title": "End-to-end preview deployment workflows with Xata and Vercel"
},
{
"id": "rec_cii1kjjjtoj0t82ae3bg",
"title": "The next era of databases are serverless, adaptive, and collaborative"
},
{
"id": "rec_cii1l1rjtoj0t82ae3cg",
"title": "Modern database workflows with GitHub, Vercel, Netlify, and Xata"
}
]
}
}
]
}Using this syntax we are able to avoid the N + 1 problem - getting all the data we want using a single request and, therefore, avoiding any unnecessary roundtrips and repetitive code.
More fields are available to configure the projection further: as, sort, limit, offset. The same request can be modified like the following:
const records = await xata.db.users
.select(["*", {
"name": "<-posts.author",
"as": "posts",
"sort": [
{ "title": "desc" }
],
"columns": ["title"],
"limit": 1,
"offset": 1
}])
.getAll();records = xata.data().query("posts", {
"columns": [
"*",
{
"name": "<-posts.author",
"as": "posts",
"sort": [
{ "title": "desc" }
],
"columns": ["title"],
"limit": 1,
"offset": 1
}
]
})// POST /db/blogs:main/tables/users/query
{
"columns": [
"*",
{
"name": "<-posts.author",
"as": "posts", // Field is returned as `posts`
"columns": ["title"],
"sort": [ // Return the nested records in this order
{"title": "desc"}
],
"limit": 1, // Limit the amount of nested records to 1
"offset": 1 // Skip first nested record
}
]
}// Response (xata fields have been omitted for clarity)
{
"records": [
{
"id": "rec_cie05krjtojbm41fv2q0",
"name": "Tudor Golubenco",
"posts": {
"records": [
{
"id": "rec_cii1kajjtoj0t82ae3ag",
"title": "Semantic or keyword search for finding ChatGPT context. Who searched it better?"
}
]
}
},
{
"id": "rec_cie05ljjtojbm41fv2qg",
"name": "Joan Edwards",
"posts": {
"records": [
{
"id": "rec_cie060jjtojbm41fv2u0",
"title": "Introducing the new Xata regions: Sydney & Frankfurt"
}
]
}
},
{
"id": "rec_cii1ki3jtoj0t82ae3b0",
"name": "Alex Francoeur",
"posts": {
"records": [
{
"id": "rec_cii1kjjjtoj0t82ae3bg",
"title": "The next era of databases are serverless, adaptive, and collaborative"
}
]
}
}
]
}For the moment, sorting options and classical pagination (limit and offset) are available for the reverse link querying. In the future, we will add support for filtering and cursor pagination. Similarly, we plan to add support for following multiple reverse links transitively. Nevertheless, for now, we know that this functionality addresses most use cases.
We evaluated three different strategies:
-
Subqueries: This approach is useful for when you need to perform operations that involve multiple tables or when you need to filter data based on the results of another query. The primary advantage is that we wouldn't have to increase the number of queries. Although, this is at the cost of introducing some complexity into the existing query and statement builder code.
-
JOINS: With this approach, we also maintain the same number of queries, but the code could become significantly more intricate, and we would need to deal with filtering out substantial amounts of duplicated data within each row.
-
N+1 queries: This approach keeps our SQL straightforward, albeit at the expense of still executing N+1 queries to the database and subsequently joining the responses together. Nonetheless, this represents an improvement because the latency (backend - PostgreSQL) is an order of magnitude lower than the latency (client - backend).
For now, we have opted for the subquery approach due to its simplicity and its adaptability for future changes if the need arises. To further simplify the process, we are leveraging the json_agg() function to get a JSON document with all the related data ready to be returned in the response.
Using subqueries in PostgreSQL simplifies complex queries, makes code more readable, avoids data duplication, and promotes code reusability. PostgreSQL's query optimizer can improve query performance with subqueries, which also support dynamic filtering, scalability with large datasets, and cross-platform compatibility through adherence to SQL standards.
The new Xata querying syntax makes it possible to traverse the N:1 relationships backwards and therefore solves the N + 1 problem in a single round-trip.
If you have feedback or questions, you can reach out to us on Discord or X/Twitter.
Subscribe to our blog
Join our community of subscribers to stay up to date with the latest news, tips and thought leadership, delivered directly to your inbox.